Social Meme-ing: Measuring Linguistic Variation in Memes
Introduction
Much work in the space of NLP has used computational methods to explore sociolinguistic variation in text. In this paper, we argue that memes, as multimodal forms of language comprised of visual templates and text, also exhibit meaningful social variation.
Highlights
We learn the semantics of meme templates without supervision. We take advantage of the multimodal structure to learn how fill text aligns with the template by fine-tuning a RoBERTa model, giving semantic embeddings for templates which we can then cluster.
We create the SemanticMemes dataset. We use this method to construct and make available a dataset of 3.8M Reddit memes grouped into semantically coherent clusters.
We find memes with socially meaningful variation. Not only do subreddits prefer certain variants of a template over others, but they choose templates that index into a localized cultural knowledge, making cultural allusions to characters or celebrities. Click below to see examples.
 r/Animemes
r/Animemes  r/memes
r/memes  r/Animemes
r/Animemes  r/dndmemes
r/dndmemes  r/PrequelMemes
r/PrequelMemes  r/startrekmemes
r/startrekmemes  r/memes
r/memes 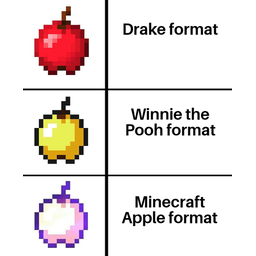 r/MinecraftMemes
r/MinecraftMemes  r/dndmemes
r/dndmemes  r/memes
r/memes What's more, we find that patterns of linguistic innovation and acculturation that have been previously observed in text also occur with memes! Read the paper for more details about these experiments, as well as our experiments with using CLIP to train a multimodal model and more information about the evaluation process.
Explore the data
You can download the dataset with Reddit post ID, image URL, RoBERTa semantic cluster label, and template visual cluster label at this link (63MB gzipped).
Use the dropdown below to view some more examples of semantic clusters.

Conclusion
We hope that this work will encourage more research into the social language of memes, and that the SemanticMemes dataset will be a useful resource for future work.
To cite this work:
@inproceedings{zhou-etal-2024-social,
title = "Social Meme-ing: Measuring Linguistic Variation in Memes",
author = "Zhou, Naitian and
Jurgens, David and
Bamman, David",
editor = "Duh, Kevin and
Gomez, Helena and
Bethard, Steven",
booktitle = "Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)",
month = jun,
year = "2024",
address = "Mexico City, Mexico",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.naacl-long.166",
pages = "3005--3024",
abstract = "Much work in the space of NLP has used computational methods to explore sociolinguistic variation in text. In this paper, we argue that memes, as multimodal forms of language comprised of visual templates and text, also exhibit meaningful social variation. We construct a computational pipeline to cluster individual instances of memes into templates and semantic variables, taking advantage of their multimodal structure in doing so. We apply this method to a large collection of meme images from Reddit and make available the resulting SemanticMemes dataset of 3.8M images clustered by their semantic function. We use these clusters to analyze linguistic variation in memes, discovering not only that socially meaningful variation in meme usage exists between subreddits, but that patterns of meme innovation and acculturation within these communities align with previous findings on written language.",
}